Public cloud is now deep in the mainstream adoption phase, research and surveys show. According to Gartner, public cloud spending is predicted to grow at a CAGR of 19% between now and 2020, and the IaaS portion in particular is predicted to grow at a CAGR of 30%. Another recent survey shows that 95% of organizations are already using cloud in some form, including 89% using public clouds.
As public cloud adoption grows, so too does the demand for diversified cloud operations, i.e. using multiple clouds. Most multi-cloud architectures involve both public and private clouds or hybrid cloud architectures. Another growing trend is the utilization of multiple public cloud providers. A recent survey shows that 20% of enterprises employ multiple public clouds in 2017, up from 16% in 2016 (a 25% growth rate). Many more are adopting multiple public clouds as part of a hybrid architecture. Organizations are running applications on 1.8 clouds, and experimenting with another 1.8 clouds, for a total of 3.6 public clouds on average.
Why Multi-Cloud?
Given the significant growth in the adoption of multi-cloud architectures, what is the motivation for operating in multiple public clouds? There are three main reasons:
- Vendor lock-in: Public cloud vendors are keen to lock in their customers. To do so, providers will use methods such as offering long-term commitments, employing asymmetric data transfer pricing, or introducing proprietary technology and services. Operating with multiple providers mitigates the effects of vendor lock-in and gives users negotiating power. Porting workloads between clouds, meanwhile, has become much simpler thanks to container technologies, and the added mobility they enable.
- Best-of-breed: Businesses may opt for a multi-cloud strategy in order to leverage the relative advantage of each provider. On the technological side, for example, organizations that have legacy workloads and applications that are Microsoft-centric (e.g. running on Windows servers) might find it easier to migrate them to Microsoft Azure, while choosing to deploy massive Hadoop workloads on AWS or Google Cloud, which are better-suited to running such workloads.
- Risk management: Outages of major public cloud providers are rare, but do happen from time to time. Even one hour of downtime can have a significant business impact on organizations with affected IT infrastructure. Operating on multiple cloud providers, along with risk management and redundancy plans, can mitigate the effect of outages on users’ business.
SLAs in a Multi-Cloud Infrastructure Environment
The Complexity of Public Cloud SLAs
In legacy on-prem deployments, all aspects of the infrastructure were in the hands of the IT departments, who controlled everything from physical hardware, operating systems, and network connectivity to security, performance, and business continuity management. Keeping all of these components in-house gave IT leaders the ability and responsibility to maintain an application SLA between them and their users.
The main challenge in migrating applications to the public cloud is maintaining the same SLA without having the same tight control over the resources. The SLA between a business and its users becomes dependent on the SLA between the cloud provider and the business. Differences between cloud providers’ performance levels and the customer SLA can therefore impact users and overall business.
Furthermore, a traditional SLA is a very strict agreement between service providers and service users, based on well-defined operational metrics for the overall service. This typically includes a penalty for breaking or underperforming from the stipulated agreements.
An SLA between cloud providers and cloud users, on the other hand, is based on an individual infrastructure’s availability. Separate availability figures are defined for virtual machines, storage, networking, and higher level services (e.g. managed databases), as well as non-negotiable compensation (paid in cloud usage credit) for availability failures. The application end-users, however, are not interested in different infrastructure availability figures, and require a single holistic SLA between them and the application/service provider.
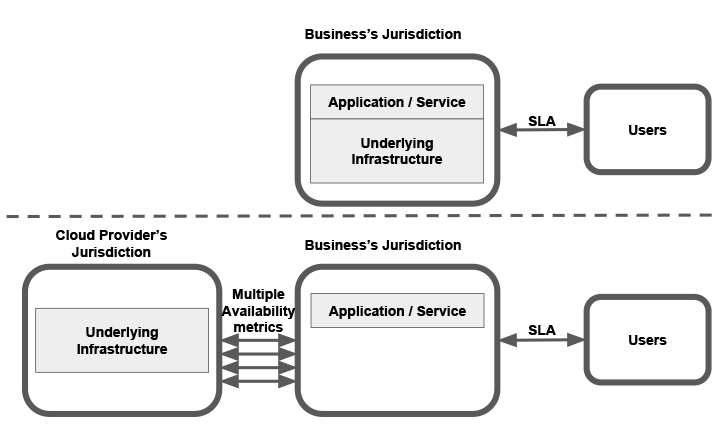
The SLA Shared Responsibility Model
A common thread that runs through everything cloud-related is the concept of shared responsibility. The term’s original use related to the basic concept of cloud technology, in which the provider was responsible for physical infrastructure and the user handled everything else: OS, data, software, etc. (The responsibility borderline is different between IaaS, PaaS, and SaaS.) The term later became popular in the context of security. It is also now used for modeling SLAs in the cloud, in which it sets the borderline between cloud providers and organizations offering cloud infrastructure-based services and applications.
Cloud providers offer availability metrics for individual resources of its infrastructure services. These availability metrics are not fully inclusive, as they sometimes don’t include downtime for scheduled maintenance and acts of “force majeure,” in which weather conditions in a small region can affect global service availability. The metrics are simply measures for individual resources, similar to what hardware manuals may have specified in legacy IT infrastructure. The responsibility of the application providers is then to use these basic metrics as input for complex, holistic SLA engineering.
The output of this process will be a required application architecture that can meet end-customer SLA requirements. Architecting considerations will then include elements like infrastructure redundancy, dedicated connectivity lines, use of CDNs, disaster recovery, and business continuity measures. In other words, cloud providers are responsible for infrastructure availability, and the application providers are responsible for architecting their application to meet application availability and SLA. Such an SLA should specify not only “X-nines” availability, but also metrics like MTBF (mean time between failures), MTTR (mean time to repair [failures]), support response times, guaranteed latency, data transfer rates, and others.
The Added Complexity of SLAs for Multi-Cloud
As if cloud SLAs weren’t complex enough, running an application in a multi-cloud environment further complicates the situation. There is no standardization in cloud SLAs, and each provider chooses their own metrics, restrictions, and exceptions with regards to service availability and standards.
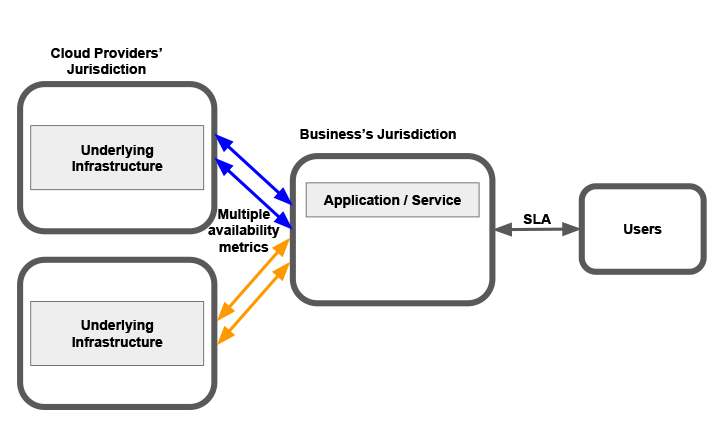
Another major challenge introduced by multi-cloud environments is the ability to determine what or who is accountable for failures. In the case of fault or unavailability, end-users will experience the same frustration or frictions regardless of the point of failure. It is the responsibility of the service provider to identify which service failed, which cloud provider was at fault, what needs to be re-architected, and who should provide compensation. For instance, which provider’s virtual machine failed versus another provider, or whose data paths introduced latency?:
One of the main considerations for succeeding in a multi-cloud environment is that there should be a single pane of glass for monitoring infrastructure and resources from multiple cloud providers. Such a platform should translate SLA metrics from different cloud providers into a common language, based on the offering and commitments from the different providers. It should also have the ability to holistically monitor an application’s infrastructure made up of different providers’ components, track and locate faults along the way, check for SLA breaches, and provide alerts for individual CSP failures. By comparing actual uptimes and other availability metrics across cloud providers, a unified cloud management platform can guide decisions for future applications to support healthy, stable, and consistent multi-cloud architecture.
Summary
Adopting a multi-cloud infrastructure environment is gaining traction with businesses looking to provide optimal customer experience while maintaining a stable business model. The complexity introduced by the cloud (compared to legacy IT) in determining and keeping in line with customer SLAs is further amplified by a multi-cloud infrastructure environment, where varied standards and blurred responsibility borderlines make it harder to track faults and properly architect applications.
Multi-cloud management platforms like CloudCheckr can mitigate this complexity by aligning all cloud providers’ commitments to a common language and system of metrics, giving organizations holistic visibility into their multi-cloud application architecture.
Explore CloudCheckr’s comprehensive cloud management platform, or start a free 14-day trial today.
Cloud Resources Delivered
Get free cloud resources delivered to your inbox. Sign up for our newsletter.
Cloud Resources Delivered
Subscribe to our newsletter