Introduction
Cloud computing environments offer customers access to seemingly endless amounts of computing resources to host their applications. While sheer scalability can help deliver a quality service to users, this ability does come with drawbacks. As an environment expands its computing resources, it becomes increasingly important to monitor how efficiently those resources are being utilized. A Gartner report noted the following:
The cloud has helped businesses improve costs in customer acquisition and customer service, reach new markets, push out new products, and minimize procurement and supply chain costs. However, without cost optimization, they could be overspending by more than 70 percent.
This guide will discuss techniques for benchmarking cloud-based environments such as AWS and Microsoft Azure and the current tools available.
Three Stages in Cloud Adoption
Most companies go through a few stages in their journey to the cloud. The three stages are as follows:
Stage 1: The Shiny New Toy
This first step is the learning stage, during which you are just beginning to learn how things work. You begin experimenting with the services that are available to you. It is similar to letting a child loose in a huge toy store. The child is initially overwhelmed, but he shortly settles down with the toys he knows and loves. The same thing can be said about using the cloud for the first time. There are so many options available to you that you might feel lost, but then you settle down with what you are accustomed to and familiar with in the datacenter: Network, Compute, and Storage.
Stage 2: Venturing out into New Worlds
At this point in the process, you have learned how to use the basic tools and you are looking to expand your knowledge and capabilities. Going back to the toy store analogy, the child knows which toys he likes to play with, but now he wants to explore new toys. He wants to try creating new combinations using his imagination. He is now the creator. In the cloud, you look to see which other services you can use to complement your current usage and make your product better. You might try using a variety of Load Balancers and storage solutions in order to create new solutions, or perhaps you will attempt to use advanced caching to improve performance.
Stage 3: Enlightenment
The third stage in the journey is where you become aware of what you have accomplished and also understand some of the errors you have made along the way. Continuing with the analogy above, the child now understands that some of the toys and imagination he used are causing problems. It could be that he is too big to play with these toys or that the toys are not doing what he originally thought they would. With AWS, a similar situation can happen when the CFO walks into your office and sees the first five- or six-digit monthly bill you received from AWS. It is also possible that your application suffered from an extended outage because the way you designed the indexes in your database did not work out as well as you had hoped.
Cloud Benchmarking
When you get to the third stage, you start to investigate some options that might help reduce the costs of your monthly Opex bill (although a long-term cost analysis could reveal that savings over an extended period of time have increased). Your costs have probably shifted from a periodic, large capital expense on hardware, services, and people to a shockingly high monthly bill.
Cost vs. Performance
In a dream world, everyone would live in the biggest houses, drive the fastest cars, and wear the most beautiful clothes. Likewise, in the cloud, every single instance would have huge amounts of RAM, CPU, and disk space attached to them, and you would have five of each to make sure that you always have enough capacity to serve your customers. Of course, this is not a realistic expectation. Not everyone can afford the biggest, fastest, or most beautiful things because all of them have a price tag attached.
The same goes for cloud resources: every single resource used in the cloud has a price tag, and the more you consume, the higher your monthly bill will be. This is not only true in regards to the quantity of services (higher number of instances)—it is also applies to quality (faster disks, larger instances, etc.).
There is always a delicate balance of how much money you are willing to pay for something you want, and it comes down to your individual preference. There are those who are willing to pay ridiculous amounts of money upfront for a high-class car because it looks nice, has a higher safety rating, and has lower fuel consumption in the long run. Others wish to pay a lesser amount because ultimately, a car really only needs to have four wheels and get you where you need to go. If the car does not have air conditioning, they will roll down the windows and enjoy the fresh air. If it needs to be serviced more often, they will take the time and get it done as needed. If it consumes more fuel, they will think twice about if the trip is really necessary; perhaps it can be postponed, or maybe they will just take the bus instead.
The same idea applies to buying and using cloud resources. If you decide to pay a large amount of money for high-end resources to run your application, you will not have to worry about “Out of Memory” (OOM) errors, insufficient CPU cycles, or choking on disk I/O. The extra money you spent on better resources saves you the effort of worrying about middle-of-the-night pages, alerts, and human resources costs for people to maintain the uptime of your environment. On the flip side, those who try to minimize their resource usage (or those who cannot afford to splurge) will have a lower monthly bill, but they run the risk of incurring significantly higher operational costs in the long run. This can not only lead to financial difficulties, but can also result in fatigue, poor employee retention, and the need to hire more skilled individuals who can support your applications 24/7.
Availability
A production-ready system is a system that is built with no single point of failure (SPOF). The success of your business depends on such a system. The car analogy we used earlier is a good one, so let us use it again. A car obviously needs four wheels in order to function as intended. What happens if one of the tires gets punctured by a nail, resulting in a flat tire? You are stuck—you cannot drive with only three wheels.
However, this would not be the end of the world. You will either stop on the side of the road and change the tire yourself or call a tow truck to do it for you. Ultimately, you will have lost some of your time, and possibly some money as well. But if a transportation truck—whose sole purpose is to move things around—had a flat tire, that lost time would result in a significant loss of business. This is why these trucks have double sets of wheels, and why some trucks even have a complete set of spare tires, just in case such an event occurs. Of course, making this resource available also has a price.
Again, the cloud is no different. If you want to host your favorite cat picture website, you might not mind too much if your site goes down for a while; but if you are hosting a mission-critical application and each minute of service downtime results in a huge loss of income (which could easily be millions of dollars for some companies), you will design your solution to survive failures and minimize the financial impact of an outage. There are a number of ways this can be accomplished, each of which has benefits and associated costs.
Availability Zones and Regions
To limit the possible impact of an outage in a single data center, you should make use of availability zones (AZs). These are usually comprised of multiple, physical data centers that are connected by a high-speed network connection, and they provide a certain amount of resilience to your solution. There have been many cases of whole regions (multiple availability zones) going down in the past, and it is in situations like these that multi-region deployment can come in handy.
However, this safety net is not free. Traffic costs are high between AZs, and are even higher between regions. Additional complications with AZs contribute to increasing costs, too: for instance, deployment becomes more complicated across multiple AZs, and database replication between regions can cause many problems due to latency.
Multiple Cloud Providers
One of the considerations we take into design is blast radius — in other words if things really go wrong, how much of your solution will be affected. One of these design principles should of course take into consideration the possibility and perhaps the necessity to deploy your application not only in different availability zones or regions, but also on completely different clouds.
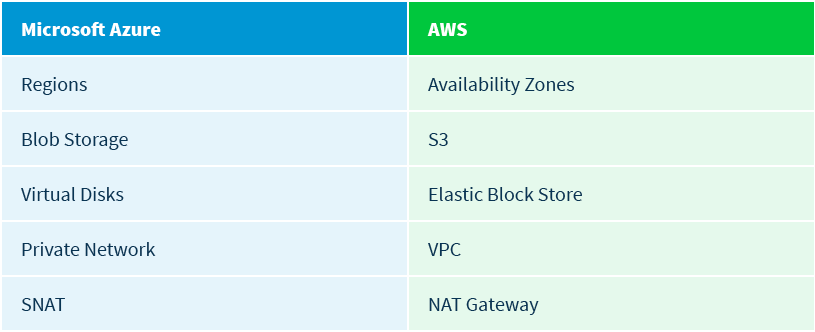
This might sound simple, but it takes a good amount of planning and design, and most importantly, the correct set of tools that will allow you to deploy across different clouds. The terminology and of course the resources used in Microsoft Azure are not the same as those in AWS – and therefore your orchestration mechanism will have to be able to provision the resources needed for your application using different API’s, across multiple clouds.
Here you can see the difference in the resources used in both clouds:
Rightsizing Your Cloud Infrastructure
In this article, we have explained the logic behind rightsizing your cloud infrastructure. The obvious question that follows is how this can be accomplished.
Flexibility
One of the huge benefits of the cloud is the elasticity and ease with which you can provision resources. Since this elasticity exists, you should not be afraid to experiment with your resource usage. You can try a high-end server for a period of time to see how your applications meet the demand from your users. If you have over- or under-provisioned, you can deploy a new instance in a matter of minutes if you use the right software. At worst, you have paid a few extra dollars for the resource usage during your trial period.
This brings up another crucial part of the equation: automation. In order to take full advantage of the cloud’s flexibility, you must be able to automate either the deployment of your resources in the cloud or the exercise of resizing resources. You can choose which tool best suits your needs and the needs of your company. Some of the most popular tools are Terraform, Ansible, and CloudFormation (AWS).
Resource Metrics
In order to know for sure whether or not your instances are starved for resources during peak times, you need to have accurate information from raw data that will allow you to make informed choices. There are a number of ways to do this analysis in the cloud, and they are usually divided between OS monitoring and cloud platform monitoring.
Collecting metrics from within the instance operating system is problematic since many instances today are throttled, and because the actual metrics collected from the instance itself will not be aware of the underlying limitations imposed on it by the platform on which it is running. In addition, there are certain metrics that can only be measured by the cloud platform since they are managed services, and you are not able to install an agent to collect any metrics for you (e.g., RDS, S3, DynamoDB). You are forced to rely on the cloud’s native metrics.
You should be aware that the cloud’s native metrics (at least for AWS EC2) do not include everything that you would expect to be available in most monitoring agents. One such example is RAM usage of your instance. AWS provides a vast set of metrics, but this set does not include everything. They do provide you with the option to expand the default metric set, but doing so comes at an additional cost. This also ties into the question of what exactly you want to measure, because measuring everything creates too much noise and makes it very difficult to pinpoint the exact metrics you want to collect.
There are a number of options available here as well: you can use the native tools (such as CloudWatch in AWS) or you can use a third party tool such as Datadog or CloudCheckr, which have the additional, built-in benefit of being able to interact with multiple clouds and aggregate information across a number of providers to give you full insight into your resource usage. If you are using Microsoft Azure – Application Insights to retrieve specific metrics from your application – or you can use Azure Monitor to allow you to make educated decisions on when you should scale your applications.
Summary
No one wants to spend more money than they need to, especially not when you are running a business and have to meet your margins and show profitability. Running a business today, cloud spending could easily become one of the biggest contributors to your overall operational expenses.
Automation allows you to make your changes quickly and frequently, allowing you the flexibility to experiment with different instance types, sizes, and configurations until you find the most cost-effective solution to suit your needs. Learn more about our automated cloud management solutions.
Cloud Resources Delivered
Get free cloud resources delivered to your inbox. Sign up for our newsletter.
Cloud Resources Delivered
Subscribe to our newsletter